



Archiving with Glacier: Key Concepts & Ways to Access Glacier’s Services
13
OCTOBER, 2017
Glacier is the best storage service to use for archiving purposes. It is cost effective, doesn’t impose size limitations and keeps your data with a durability that makes it almost impossible for it to lose data. Glacier can be used for storing various kinds of data: enterprise logs, IP video surveillance records, data analytic logs, research logs and more.
Before employing this storage tier, it is necessary to have an understanding of Glacier so you can utilize it to its fullest potential.
Amazon Glacier: Key Concepts
Several cleverly thought constituents make up the ever proficient storage tier for archiving. The following are the key concepts:

Account at Glacier
If you are completely new to Glacier, then this is the first step. You have to make up an account with Glacier. This account lets you view billing and consumed storage space. This is also where you can configure your security, which is very important for secure data archiving. Once you have setup your account and all your settings, you can use Glacier’s services.
Vaults – Archiving Containers
Vaults are containers for storing Glacier archives. You can create up to a 1000 vaults per account. If you wish to acquire more vaults, then you have to make more accounts. Within a vault, you can store as many archives as you require.
Remember, an Archive is a collection of bytes. You can store a picture or movie as an archive or you can bunch them together in a single file by compressing them into a .zip or .rar file. There are no limits on the number of archives but there is a file size limit on an archive. An individual archive can be from 1 byte to 40 terabytes (TB).
Inventory – Index of Archived data
It is common practice to maintain a log/index file about the data archived. Glacier also creates such a file, as inventory, of all archived data within a vault. This is maintained for disaster recovery or occasional reconciliation purposes. Each vault’s inventory is updated approximately once in 24 hours.
You can retrieve this inventory file in either .JSON or .CSV file format. The file will contain details about the archives within the vault including size, creation date and archive description (if provided during upload).
These are the main ingredients that constitute Glacier and its archiving services.
3 ways to Access Amazon Glacier
There are three ways you can gain access to Glacier and archive your data.

Direct Glacier Application Platform Interface (API)
As with any Amazon service, you gain full access to all the controls using the API. Glacier is very flexible and it enables you to build applications. There are two major concerns of the Glacier user: uploading and retrieving data. These concerns are constant regardless of your application of Glacier’s services. You can be an enterprise looking to archive analytics or operational data for compliance regulations. Or you can be an individual or enterprise using Glacier for IP video archiving.
Uploading data into Glacier using API

The first step is to create vaults, also referred to as films. You can upload data after creating a vault but it is highly recommended that before you do, you should configure your security policy. This is because when considering data that you are not going to be accessing frequently, it is necessary to manage accessibility of this data. Who can access the data and who can delete it are important considerations that need to be made. Once you’ve made sure that the security policy is in accordance to your preferences, you can upload your data using the API.
After you have uploaded the file, an archive ID for the file will be created in the inventory. You can also keep this ID in your local indexing system to allow you to track specific archives over multiple vaults.
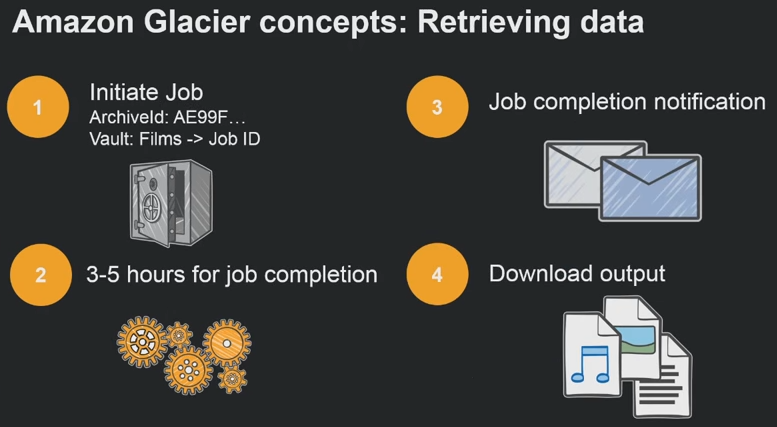
Retrieving data from Glacier using API
Data retrieval is a less frequently used process for Glacier, since it is an archiving storage tier. When initiating the retrieval job, you will have to mention the archive ID of the file or files you wish to recover. After the initiation process, it takes about 3 to 5 hours to retrieve your selected files. Once the process is completed, you receive a notification and you can download your archived files.
S3 – Life Cycle Integration
If you’re already using Amazon’s S3 storage tier then moving data to Glacier is very simple. This is called lifecycle capability. Due to the recent launch of the infrequent access tier (S3-IA), users now have three tier options to move their data in. Using simplistic commands, you can determine when certain data moves from S3 to S3-IA and then from S3-IA to Glacier until finally it’s deleted.

In the above example, logs are moved from S3 to S3-IA, then after 30 days it is archived into Glacier. After this data has been retained in Glacier, the data is deleted. This is just an example; users can have their own settings as per their company policy and industry regulations.
This integration makes Amazon cloud storage services an essential part of an efficient and cost effective backup and disaster recovery plan.
Third Party Tools & Gateways
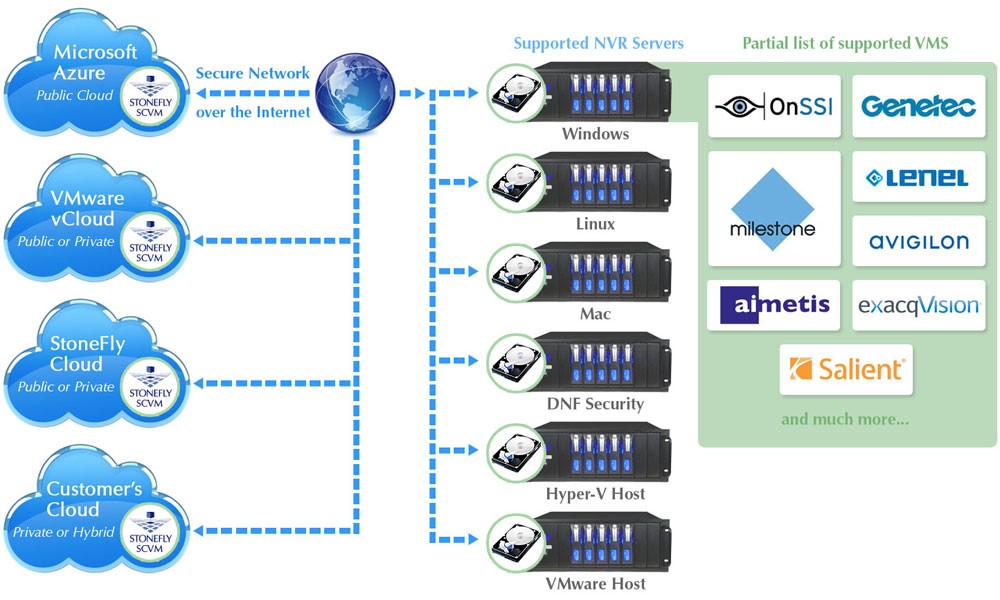
There are third party service providers that enable existing infrastructure to connect with Amazon’s Glacier storage tier. One such capable service provider is StoneFly. Using StoneFly’s SCVMTM (storage controller virtual machine) DNF security’s Network Video Recorders (NVRs), backup your video data into Glacier. This isn’t just applicable to IP video archiving; StoneFly’s products and services have a broad range of applications.
Summary
Amazon comprises of various different concepts, there are a few key concepts that are at the center of the whole concept of Glacier. First, if you’re new to Glacier, you need an account. This account lets you manage your billing and usage; it also enables to manage your security policies. After the creation of an account, you are able to create vaults; these vaults are used for storing your archives. You can have 1000 vaults per account and each vault can store an unlimited amount of archives. There are no limitations on archives; however, an archive cannot exceed the size limitations of 40TB. Glacier maintains an inventory; this inventory is a list of indexes of your archived data. It is updated once every 24 hours.
There are three ways of accessing Glacier’s archiving services. One is using Amazon’s direct API. It allows you to upload and retrieve data. In order to upload data, you have to create a vault, set your security policies and then you can upload your data. It is crucial that you scrutinize the security and accessibility policies of this created vault. The retrieval process requires 3 to 5 hours of processing and it also requires the archive ID of the file you wish to retrieve. Once the file is ready to be downloaded, the API displays a notification.
Another way to access Glacier’s features is by using S3’s lifecycle capability. It is convenient for users who are already using S3. They can choose to move their data, based on a certain data or time period from one storage tier to the other. The third way of accessing Glacier is using third party tools and gateways. An example of an efficient and convenient third party gateway is StoneFly’s SCVM that pairs up with DNf security’s NVRs resulting in DNF cloud connection services. Using this gateway, DNF security products are able to archive recorded data directly into Glacier.
